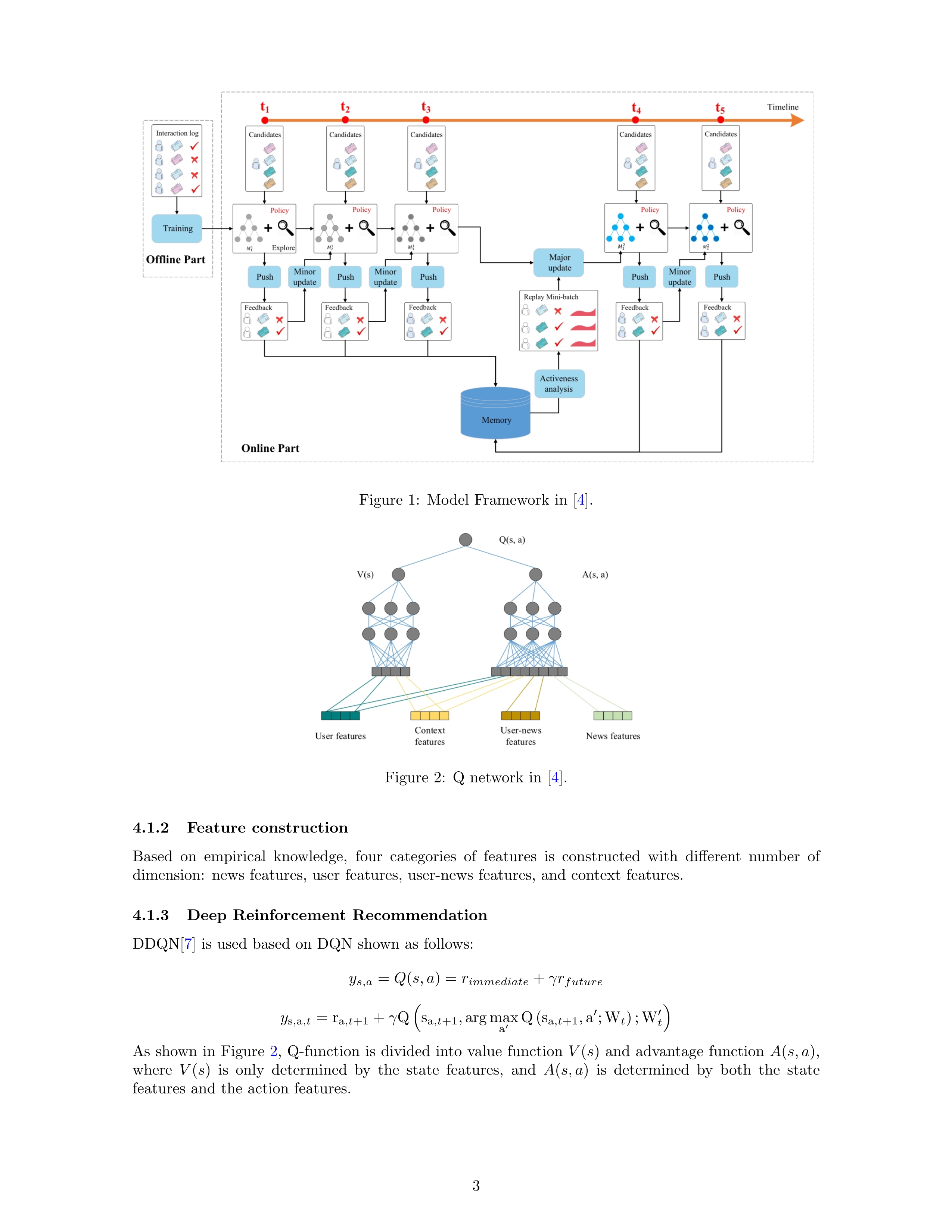
PMF explains the latent factor of user and item from the perspective of the probability generation process. SVD++ starts from the optimization goal. How to determine the latent factor of user and litem can minimize the loss. The interpretation methods of the two are different, but the MLE of PMF is equivalent to the loss function of optimizing SVD++ with regular term. From the perspective of optimization and implementation, there is no difference between the two.
2. Pseudo-code Algorithm
Part II: the results of SVD++ algorithm
1. Results by 5-fold cross validation
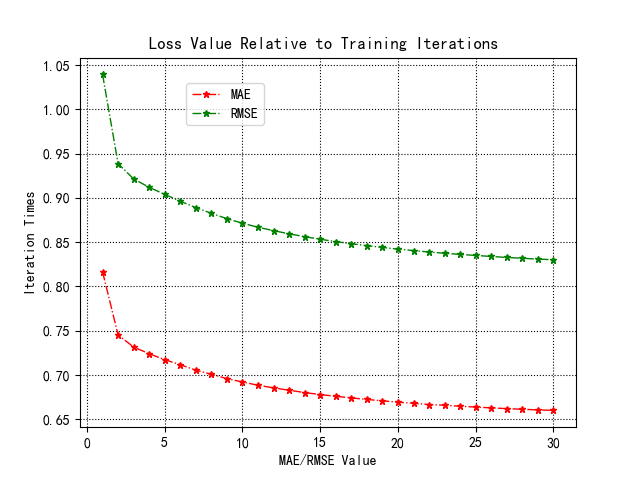
MAE
RMSE
Train time (s)
Test Time (s)
0.1816
0.9143
17970
3.58
Learn rate
Factors
Iterations
0.04
20
30
2. The curve of loss value relative to training iterations
Reference
[1] Koren, Yehuda. "Factorization meets the neighborhood: a multifaceted collaborative filtering model." Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 2008.
ernational conference on Knowledge discovery and data mining*. 2008.
Report of Reinforcement Learning in Recommender System